

爬虫工具包,爬虫工具如何使用
1 Arachnid一个基于Java的web spider框架,包含一个小型HTML解析器通过实现Arachnid的子类开发简单的Web spiders,并在解析网页后增加自定义逻辑下载包中包含两个spider应用程序例子特点微型爬虫框架,含有一个小型HTML解析器许可证GPL2 crawlzilla一个轻松建立搜索引擎的自由软件,拥有中。
12 Fiddler,一个。
1八爪鱼,国内知名且业界领先的网络爬虫软件其多场景适应性,以及丰富的功能如模板采集智能采集云采集等,使其成为众多职业人士的首选2火车头,以高灵活度和强大性能著称,深受用户喜爱其分布式高速采集系统,打破操作局限,高效提升效率适用于数据抓取处理分析及挖掘3集搜客GooSeeker。
selenium可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题 二selenium基本使用 用python写爬虫的时候,主要用的是selenium的Webdriver,我们可以通过下面的方式先看看SeleniumWebdriver支持哪些浏览器 执行结果如下,从结果中我们也可以看出基本山支持了常见的所有浏览器 这里要说一。
a Firebug虽能抓包,但对于深入分析。
WebSPHINXWebSPHINX是一个Java爬虫开发环境,由爬虫工作平台和WebSPHINX类包组成它提供可视化显示页面集合下载页面按规则抽取文本字符串开发自定义爬虫等功能通过WebSPHINX,开发者可以更直观地进行Web页面的爬取与处理WebLechWebLech是一款功能强大的Web站点下载与镜像工具,采用多线程操作适合初学者。
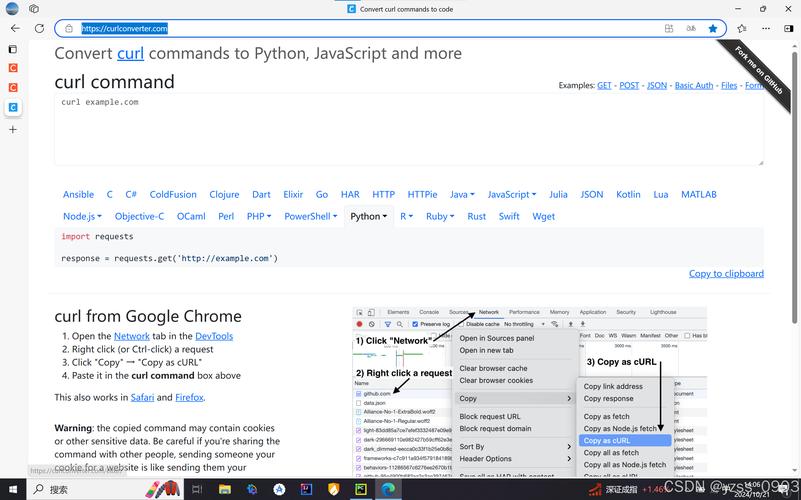
工具与视图 编辑器提供两种模式,Inspectors展示请求和响应头,AutoResponderFiddler则用于拦截和重定向资源过滤与隐藏 强大的过滤功能支持按状态码类型等条件筛选,隐藏本地请求或特定服务器响应断点与响应修改 设置断点进行模拟测试,如修改响应内容并在完成后运行脚本与时间线 利用Fiddler script。
Goose最早是用Java写得,后来用Scala重写,是一个Scala项目PythonGoose用Python重写,依靠了Beautiful Soup给定一个文章的URL, 获取文章的标题和内容很便利,用起来非常nice以上就是Python编程网页爬虫工具集介绍,希望对于进行Python编程的大家能有所帮助,当然Python编程学习不止需要进行工具学习,还有。
深入探索R语言爬虫技术,尝试使用rvest包与SelectorGadget工具,对自如租房网站的北京租房数据进行爬取工具准备包含rvest包谷歌浏览器以及SelectorGadget定位工具rvest包内包含管道函数read_htmlhtml_nodes与html_text等关键功能,分别用于数据读取选择与文本提取下载谷歌浏览器并安装SelectorGadget。
Python爬虫,全称Python网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或脚本,主要用于抓取证券交易数据天气数据网站用户数据和图片数据等,Python为支持网络爬虫正常功能实现,内置了大量的库,主要有几种类型下面本篇文章就来给大家介绍一Python爬虫网络库Python爬虫网络库主要包括。
爬虫工具有很多种,包括但不限于ChromeCharlescUrlPostmanOnline JavaScript BeautifierEditThisCookieSketchXPath HelperJSONViewJSON Editor OnlineScreenFloat等此外,还有专门的爬虫框架如ScrapyPySpiderCrawleyPortia等首先,Chrome等浏览器工具是爬虫的基础,用于初始的爬取分析,如。
这是Windows系统下一个非常不错的网络爬虫软件,个人使用完全免费,集成了数据的抓取处理分析和挖掘全过程,可以灵活抓取网页上散乱的数据,并通过一系列的分析处理,准确挖掘出所需信息,下面我简单介绍一下这个软件1首先,安装火车头采集器,这个直接在官网上下载就行,如下,安装包也就30M左右。
数据爬虫,作为互联网数据抓取的重要工具,通过网络爬虫技术实现高效信息获取和解析网络爬虫包括“好爬虫”和“坏爬虫”,前者遵循规则,后者则可能带来潜在问题爬虫技术主要包括发起请求获取响应内容解析内容保存数据以及应用数据等步骤市面上有许多开源免费的爬虫工具,例如Content Graber,提供了C#。
Mitmproxy 的优势体现在其与 Python 的无缝集成,允许开发者编写脚本来处理抓取的数据这种结合使得 Mitmproxy 成为一款强大且灵活的工具,不仅适用于 App 爬虫,还能在数据抓取测试和安全审计等领域发挥重要作用通过 Mitmproxy,开发者能够更高效地进行数据收集与分析,提升开发与测试效率。
1Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中 2pyspider 是一个用python实现的功能强大的网络爬虫系统,能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储。
作为数据抓取领域的常青树,火车头凭借灵活配置和强大性能赢得了众多用户喜爱它不仅可以采集网页,还能处理和分析数据,用户扩展性极强价格每年从960元起,性价比高,是数据采集领域的性价比之选3 集搜客GooSeeker 早期的创新者与现代技术的融合 作为国内早期的网络爬虫工具,集搜客GooSeeker近年来。
网络爬虫框架 1功能齐全的爬虫 ·grab网络爬虫框架基于py curlmulti cur ·scrap y网络爬虫框架基于twisted , 不支持 Python 3mpy spider一个强大的爬虫系统·cola一个分布式爬虫框架2其他 ·portia基于Scrap y的可视化爬虫rest kitPython的。
它的特性有HTML, XML源数据 选择及提取 的内置支持提供了一系列在spider之间共享的可复用的过滤器即 Item Loaders,对智能处理爬取数据提供了内置支持2Crawley高速爬取对应网站的内容,支持关系和非关系数据库,数据可以导出为JSONXML等3Portia是一个开源可视化爬虫工具,可让使用者。
相关文章
发表评论
评论列表
- 这篇文章还没有收到评论,赶紧来抢沙发吧~